Adoptée le 23 mars 2019, la loi n° 2019-222 de programmation 2018-2022 et de réforme pour la justice a enclenché par son article 33 un processus de mise à disposition gratuite sous forme électronique des décisions des juridictions françaises. Elle a été complétée par deux décrets touchant à la mise en oeuvre pratique de cette exigence (Décret n° 2020-797 du 29 juin 2020 relatif à la mise à la disposition du public des décisions des juridictions judiciaires et administratives et Décret n° 2021-1276 du 30 septembre 2021 relatif aux traitements automatisés de données à caractère personnel dénommés « Décisions de la justice administrative » et « Judilibre »). Tandis que le Conseil d’Etat ne met pour le moment en ligne qu’en ensemble de fichiers XML chronologiquement organisés (https://opendata.conseil-etat.fr/), la Cour de cassation a développé une API (interface de programmation applicative), c’est-à-dire une interface de communication avec sa base de données, ouverte aux logiciels et services tiers. Cette API, dénommée « Judilibre », est hébergée par la plateforme PISTE, gérée par l’Agence pour l’Informatique Financière de l’Etat et qui héberge également l’API du site Légifrance.
Toute personne intéressée peut s’enregistrer auprès de PISTE pour pouvoir ensuite utiliser les API qui sont hébergées et les intégrer dans une application / logiciel qui pourrait en tirer profit. C’est notamment ce que j’ai fait pour le développement d’un petit site internet d’extraction de jurisprudences à partir d’un fichier docx ou pdf (https://reglex.fondamentaux.org/). Après un phase d’analyse du texte pour reconnaître les décisions de justice qui y sont mentionnées, cette application se connecte à l’API pertinente pour identifier les liens web vers les textes des décisions en cause et les afficher à l’internaute. Au-delà des API « officielles » Légifrance et Judilibre, l’application se connecte également à deux autres API « secrètes » ou du moins ne bénéficiant d’aucune documentation officielle : ArianneWeb (Conseil d’Etat) et Hudoc (Cour européenne des droits de l’Homme). La Cour de justice de l’Union européenne dispose également d’une API (EUR-LEX Web Service), mais sa lourdeur de mise en oeuvre m’a pour le moment repoussé.
Pour les personnes intéressées, je souhaite détailler ici les modalités d’utilisation de ces différentes API, leur facilité ou non de mise en oeuvre et leurs limites, en commençant par Légifrance, pour continuer par Judilibre, ArianneWeb et finir avec Hudoc. Juste avant, je voudrais revenir rapidement sur la manière dont un site web peut communiquer avec une API.
Communiquer avec une API
Communiquer avec une API, c’est envoyer une requête à une adresse internet (URL) donnée et attendre une réponse dans un format prédéterminé. Certaines API sont interrogeables de manière complètement ouverte (Hudoc et ArianneWeb par exemple), d’autres nécessitent l’utilisation d’identifiants que l’on aura obtenu par avance (les API de la plateforme PISTE). Dans tous les cas, il est donc nécessaire d’identifier :
- L’URL de communication de l’API (par exemple : https://api.piste.gouv.fr/dila/legifrance-beta/lf-engine-app/search pour Légifrance) ;
- Le type d’API (REST ou SOAP). Toutes les API utilisées ici sont des API REST, REST étant aujourd’hui le style d’architecture logicielle le plus utilisé pour les API ouvertes ;
- La méthode de requête du protocole Http (POST ou GET) utilisée par l’API. Certaines API n’acceptent a priori que l’une des deux méthodes (Légifrance travaille en POST, Judilibre en GET), d’autres acceptent les deux (ArianneWeb par exemple). Ces méthodes ne sont pas propres aux API et on les rencontre tous les jours dès lors que l’on transmet une information à un site par un formulaire de recherche, de contact… ;
- Le format des données pour l’envoi de la requête. Dans la plupart des cas, les données de requête seront envoyées au format JSON et/ou au format URL. Pour ce dernier format, nous l’avons toutes et tous déjà rencontré lorsque nous naviguons sur certains sites où figure à la fin de l’adresse un point d’interrogation suivi de mots. Par exemple, lorsque l’on fait une recherche sur le site Légifrance, la page de résultat va afficher une URL du type https://www.legifrance.gouv.fr/search/all?tab_selection=all&searchField=ALL&query=internet&page=1&init=true. Dans cette adresse, tout ce qui vient après le point d’interrogation renvoie à des données de requête GET. Grâce à cela, le site internet est capable d’afficher les informations demandées. En l’espèce, par exemple, le site Légifrance va donc m’afficher la première page (page=1) d’une recherche sur le terme « internet » (query=internet) dans tous les contenus du site (tab_selection=all) et sur tous les champs de la base de données (searchField=ALL). Si j’avais limité ma recherche à la table des matière des codes, l’adresse aurait alors été ?tab_selection=code&searchField=TABLE…
- Le format des données reçues en retour de la requête. Aujourd’hui, presque toutes les API REST utilise le JSON comme format de retour des données. C’est le cas pour toutes les API présentées ici.
Ensuite, le développeur du site internet choisit le langage de programmation qu’il va utiliser pour interroger l’API (Php, Javascript, Python…). Ce choix dépend de l’architecture du site internet en cause (et des compétences du développeur). Pour l’application REGLEX, j’ai par exemple utilisé le Php qui est le langage le plus utilisé pour développer des sites internet (environ 80% des sites internet dans le monde utilisent le Php), associé à la bibliothèque libcURL permettant la connexion à un site tiers.
API Legifrance
L’API Legifrance permet d’accéder à l’ensemble des données disponibles sur le site Légifrance. Hébergée par le portail PISTE, elle nécessite donc une identification pour pouvoir être utilisée. Elle doit être interrogée par une requête POST incluant des données de requête au format JSON. Malheureusement, la documentation présente plusieurs erreurs (par exemple, le fond pour les arrêts du Conseil d’Etat est « CETAT » et non « CETA », plusieurs valeurs de filtres sont mal identifiées…) et le formatage JSON des données n’est pas du tout intuitif. Voici par exemple les données JSON d’une requête pour récupérer deux arrêts du Conseil d’Etat identifiés par leur numéro de requête :
{« fond »: »CETAT », »recherche »:{« champs »:[{« criteres »:[{« typeRecherche »: »EXACTE », »valeur »: »123709″, »operateur »: »OU »},{« typeRecherche »: »EXACTE », »valeur »: »241781″, »operateur »: »OU »}], »typeChamp »: »NUM_DEC », »operateur »: »OU »}], »operateur »: »OU », »typePagination »: »DEFAUT », »pageNumber »:1, »pageSize »:20, »sort »: »DATE_ASC »}}
Certains détails sont inutilement compliqués, voire juste inutiles. C’est dommage, car cela rend d’autant plus difficile le travail du développeur qui souhaite utiliser l’API (j’avoue avoir passé un certain temps à tester différents formats, avant de recevoir une réponse positive de l’API). Une fois que l’on a passé cette difficulté, cela fonctionne bien, même si les données reçues ne sont pas toujours uniformisées (toutefois ce n’est pas un problème dû à l’API, mais à l’enregistrement des données des cours de justice dans la base de données Légifrance). Rien n’est réellement normé et cela rend l’exploitation de ces données problématique si l’on veut aller au-delà de la simple recherche d’une URL vers le texte de la décision.
API Judilibre
Petite dernière dans le champs des API de juridictions, Judilibre est l’API développé par les services de la Cour de cassation pour la mise en open data des décisions de justice de l’ordre judiciaire. Hébergée par la plateforme PISTE, elle nécessite une identification pour pouvoir être utilisée (comme pour Légifrance). Elle doit être interrogée par une méthode GET avec un format de donnée de requête très simple. Une recherche d’un arrêt de la Cour de cassation par son numéro de pourvoi (ici 14-822.34) se fait simplement par la requête https://api.piste.gouv.fr/cassation/judilibre/v1.0/search?query=14-822.34. Bref et efficace. De nombreux filtres sont disponibles (type de décision, juridiction, dates…).
Un petit bémol doit pour le moment être apporté. Il n’est en effet à leur actuelle pas encore possible de faire une seule et même requête pour récupérer plusieurs décisions à partir de leurs numéros d’affaire respectifs. Ainsi la requête https://api.piste.gouv.fr/cassation/judilibre/v1.0/search?query=14-822.34%2015-84.940&operator=or renverra un résultat nul. C’est problématique pour une utilisation dans une application comme REGLEX dès lors que la recherche de plusieurs décisions va impliquer autant d’appels à l’API (en lieu et place d’un appel unique avec de multiples numéros). Cela entraîne des requêtes inutiles et ralentit d’autant l’affichage du résultat.
API ArianneWeb
ArianneWeb est la base de jurisprudence du Conseil d’Etat qui recense plus de 250000 décisions et avis du Conseil, du Tribunal des conflits et des Cours administratives d’appel. Elle n’est pas exhaustive mais se limite aux décisions ayant un intérêt jurisprudentiel. Au départ, ArianneWeb n’est pas conçu comme une API (aucune documentation n’est disponible en ce sens), mais en fouillant un peu dans les entrailles du site, il est possible d’identifier tous les éléments à même de nous permettre de l’utiliser comme tel.
En utilisant l’outil d’inspection de Firefox lors d’une requête sur ArianneWeb (nous recherchons ici l’arrêt du Conseil d’Etat avec le numéro d’affaire « 123709 »), on se rend compte que le serveur fait un appel POST initié par XHR sur l’URL https://www.conseil-etat.fr/xsearch?type=json (cf. image ci-dessous).
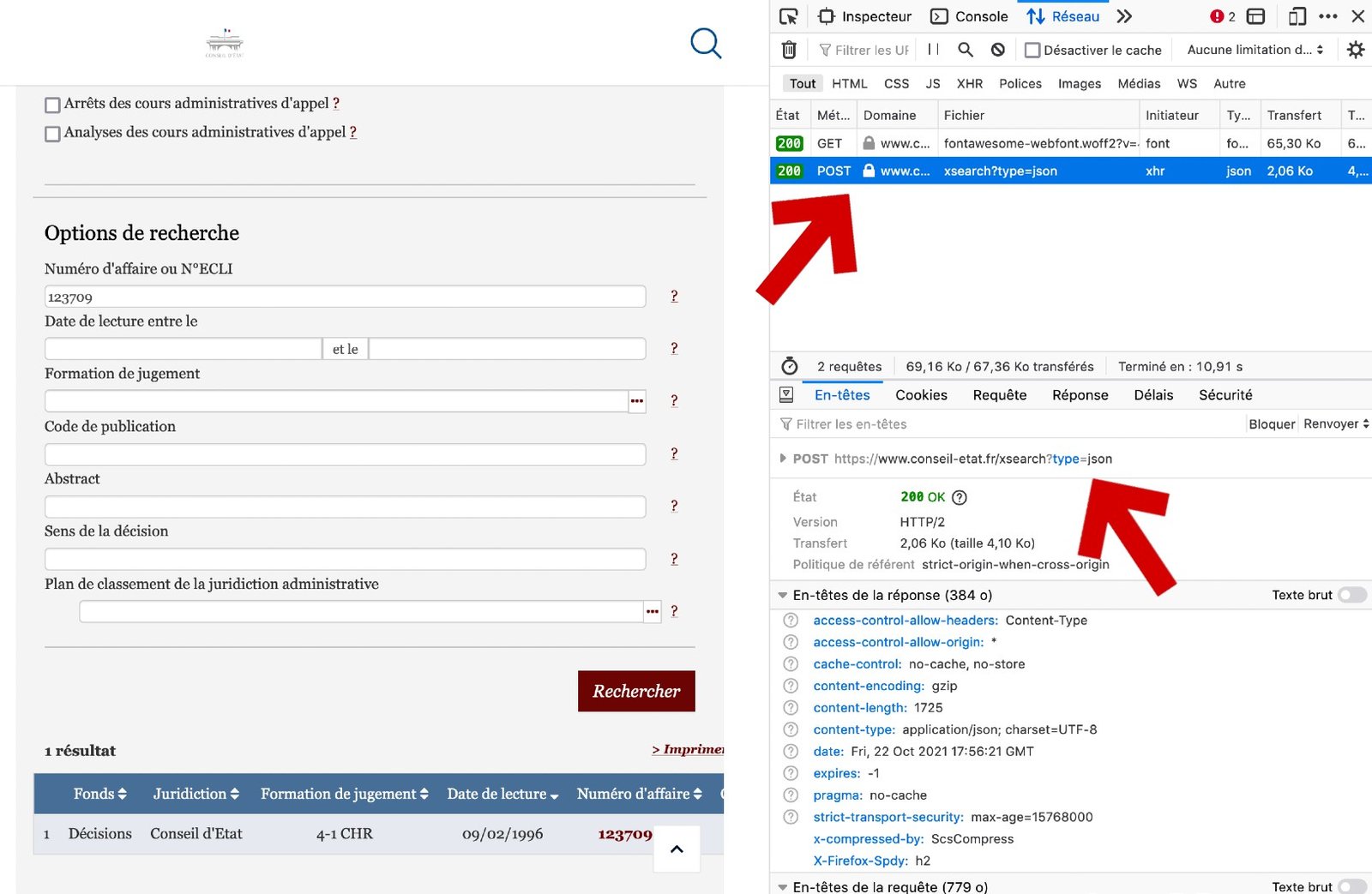
XHR est l’abréviation de XMLHttpRequest, un protocole javascript de communication avec une API. C’est donc qu’une telle API existe pour ArianneWeb. Dans l’onglet « Requête » de l’inspecteur, on obtient les données envoyées à cette API pour notre recherche. Ce qui donne :
 On apprend ici plusieurs choses importantes :
On apprend ici plusieurs choses importantes :
- « SourcesStr4 » correspond au fond recherché (ici les décisions du Conseil d’Etat avec le code « AW_DCE »). Pour le Tribunal des conflits, c’est en fait « AW_DTC » et pour les CAA, c’est « AW_DCA ».
- « sourcecsv1 » correspond au numéro d’affaire
Dans l’onglet « Réponse », on a accès au données JSON renvoyées par l’API. Comme la réponse inclut un rappel de la requête initiale (« Query »), on y voit le format que doit prendre nos données JSON à envoyer en POST (ci-dessous).
 On y trouve également les deux arrêts renvoyés, avec toutes les informations utiles à exploiter (date de l’arrêt, parties, avocats, rapporteur public, type d’arrêt…).
On y trouve également les deux arrêts renvoyés, avec toutes les informations utiles à exploiter (date de l’arrêt, parties, avocats, rapporteur public, type d’arrêt…).

Avec tout ceci en main, la première étape est de vérifier que l’API est ouverte et qu’une requête est donc possible depuis un serveur tiers. On va alors utiliser un petit outil pour tester une requête cURL sur l’adresse de base (https://www.conseil-etat.fr/xsearch?type=json) et voir la réponse (cela nous permet de tester si le site accepte des requêtes de sites tiers). Le site nous répond avec un code « 200 » (requête valide) et nous renvoie la liste de l’ensemble des documents disponibles sur ArianneWeb (285200 documents sur 14260 pages).
 L’API est bien ouverte et nous allons pouvoir l’utiliser. Mais avant de m’engager dans une requête POST, j’ai voulu vérifier si une requête GET était possible (dans ce cas-là, on peut éviter le formatage en JSON des données à transmettre). Même réponse que pour la requête POST, cette API accepte ainsi les deux méthodes. Pour créer notre requête GET, il nous suffit de revenir sur l’onglet « Requête » de l’inspecteur de Firefox, de cliquer sur « Texte brut » et on obtient la requête en format URL
L’API est bien ouverte et nous allons pouvoir l’utiliser. Mais avant de m’engager dans une requête POST, j’ai voulu vérifier si une requête GET était possible (dans ce cas-là, on peut éviter le formatage en JSON des données à transmettre). Même réponse que pour la requête POST, cette API accepte ainsi les deux méthodes. Pour créer notre requête GET, il nous suffit de revenir sur l’onglet « Requête » de l’inspecteur de Firefox, de cliquer sur « Texte brut » et on obtient la requête en format URL
advanced=1&type=json&SourceStr4=AW_DCE&text.add=&synonyms=true&scmode=smart&sourcecsv1=123709&SkipCount=50&SkipFrom=0&sort=SourceDateTime1.desc,SourceStr5.desc
On fait un petit test cURL pour voir si la requête fonctionne.
 Tout fonctionne, on va pouvoir utiliser cette API pour notre application REGLEX. Il est vrai que les données exploitables sont limitées (juridiction, date de la décision, parties, type de décision…) mais c’est suffisant pour ce que nous voulons en faire.
Tout fonctionne, on va pouvoir utiliser cette API pour notre application REGLEX. Il est vrai que les données exploitables sont limitées (juridiction, date de la décision, parties, type de décision…) mais c’est suffisant pour ce que nous voulons en faire.
API Hudoc
Hudoc est le moteur de recherche de la Cour européenne des droits de l’Homme. Là encore, aucune API officielle n’est documentée, mais tout comme pour ArianneWeb, il est possible d’exploiter ce moteur comme une API. En inspectant une recherche sur Hudoc, on s’aperçoit de l’existence d’une requête GET initiée par XHR (ci-dessous).
 Lorsque l’on clique sur cet élément, on obtient la requête envoyée (comme c’est une requête GET, tout apparaît dans l’URL).
Lorsque l’on clique sur cet élément, on obtient la requête envoyée (comme c’est une requête GET, tout apparaît dans l’URL).

Dans l’onglet « Réponse », on obtient toutes les données JSON renvoyées par l’API pour l’arrêt en cause.
 Il nous reste juste à vérifier que cette API est interrogeable à partir d’un site web tiers. Pour cela, il faut commencer par réencoder l’url GET, car celle qui apparaît dans l’inspecteur Firefox présente notamment des espaces (ce qui en facilite la lecture mais n’est pas compris par une API). Au bon format, cela donne l’URL suivante :
Il nous reste juste à vérifier que cette API est interrogeable à partir d’un site web tiers. Pour cela, il faut commencer par réencoder l’url GET, car celle qui apparaît dans l’inspecteur Firefox présente notamment des espaces (ce qui en facilite la lecture mais n’est pas compris par une API). Au bon format, cela donne l’URL suivante :
https://hudoc.echr.coe.int/app/query/results?query=contentsitename%3AECHR%20AND%20%28NOT%20%28doctype%3DPR%20OR%20doctype%3DHFCOMOLD%20OR%20doctype%3DHECOMOLD%29%29%20AND%20%28%28appno%3A%2237553%2F05%22%29%29%20AND%20%28%28documentcollectionid%3D%22JUDGMENTS%22%29%20OR%20%28documentcollectionid%3D%22DECISIONS%22%29%29&select=sharepointid,Rank,ECHRRanking,languagenumber,itemid,docname,doctype,application,appno,conclusion,importance,originatingbody,typedescription,kpdate,kpdateAsText,documentcollectionid,documentcollectionid2,languageisocode,extractedappno,isplaceholder,doctypebranch,respondent,advopidentifier,advopstatus,ecli,appnoparts,sclappnos&sort=&start=20&length=100&rankingModelId=22222222-ffff-0000-0000-000000000000
Une petite requête sur Reqbin.com nous montre que l’API est ouverte. C’est parfait, on va pouvoir l’utiliser également.

Voilà, j’en finis par-là cette balade dans le monde merveilleux des API des cours de justice françaises et européennes. Dans un prochain post, j’évoquerais la Regex qui est au coeur de l’application REGLEX et qui permet d’identifier les jurisprudences dans un texte.
Commentaires